The most simple Machine Learning Pipeline
Today, we walk thru a basic machine learning pipeline including a train/test split and make use of a random search to conduct a hyperparameter tuning. This architecture is the backbone of many statistical machine learning tasks and hence usefuls as to keep close-by as a code-snippet!
1 | # load modules and get a data set |
1 | # ds-econ style sheet! |
The Basic Machine Learning Pipeline
The first step in our mini “pipeline” is to split the data set into training and test set. This splitting of the data is important, to prevent overfitting and have an evaluation of the model which reprensents its real-life performance more closely. We can do this in a neat way with sklearn’s model_selection.train_test_split.
1 | from sklearn.model_selection import train_test_split |
Next, we initialize our model. We use sklearn’s linear_model.LogisticRegression here, but choice is arbitrary for this example.
Go take a look at the documentation of scikit-learn, for information on all models and other useful machine learning functions contained in this seminal package!
We initialize the model with fixed hyperparameters, fit it to the training data (i.e. X_train & y_train) and then we make a prediction with the model on the test data i.e. X_test. Below, we then use the labels of the test set (y_test) to evaluate the models performance with metrics.accuaracy_score.
Note: the test set is not used to train the model - It is used to evaluate it!
1 | # train the model on the training data |
1 | from sklearn.metrics import accuracy_score |
The models accuracy is: 0.904
Getting More Complex: Adding Hyperparameter-Tuning
After walking through the example code above, you might have asked yourself: “How do we pick the hyperparameters though?”. While there are general rules-of-thumb for some algorithm’s hyperparameters out there, a good appraoch in either case is to make use of Hyperparameter-Tuning with Cross-Validation. You can read more about this topic in this Towards-Data-Science Article
In this example we use RandomizedSearchCV, which randomly chooses configurations of hyperparameters out of a prespecified set (the dictionary: dist_param). You can read more about the details of this function in its documentation.
For this second part, we use a different model just to switch things up. Here, we use a Decision-Tree: DecisionTreeClassifier.
1 | from sklearn.model_selection import train_test_split |
1 | from scipy.stats import norm |
To conduct the RandomizedSearchCV, we first specify the type of model we want to use and pass any hyperparameters that we want to fix for it here. In a second step, we pass this model into RandomizedSearchCV and fix some options of the cross-validation, like the number of cv-splits or which random_state to use.
1 | # train the model on the training data |
Fitting 3 folds for each of 5 candidates, totalling 15 fits
[CV 1/3] END ...criterion=entropy, max_depth=20;, score=0.924 total time= 0.0s
[CV 2/3] END ...criterion=entropy, max_depth=20;, score=0.920 total time= 0.0s
[CV 3/3] END ...criterion=entropy, max_depth=20;, score=0.928 total time= 0.0s
[CV 1/3] END ......criterion=gini, max_depth=10;, score=0.932 total time= 0.0s
[CV 2/3] END ......criterion=gini, max_depth=10;, score=0.924 total time= 0.0s
[CV 3/3] END ......criterion=gini, max_depth=10;, score=0.948 total time= 0.0s
[CV 1/3] END .......criterion=gini, max_depth=5;, score=0.944 total time= 0.0s
[CV 2/3] END .......criterion=gini, max_depth=5;, score=0.944 total time= 0.0s
[CV 3/3] END .......criterion=gini, max_depth=5;, score=0.960 total time= 0.0s
[CV 1/3] END ...criterion=entropy, max_depth=10;, score=0.924 total time= 0.0s
[CV 2/3] END ...criterion=entropy, max_depth=10;, score=0.920 total time= 0.0s
[CV 3/3] END ...criterion=entropy, max_depth=10;, score=0.928 total time= 0.0s
[CV 1/3] END .......criterion=gini, max_depth=1;, score=0.924 total time= 0.0s
[CV 2/3] END .......criterion=gini, max_depth=1;, score=0.912 total time= 0.0s
[CV 3/3] END .......criterion=gini, max_depth=1;, score=0.916 total time= 0.0s
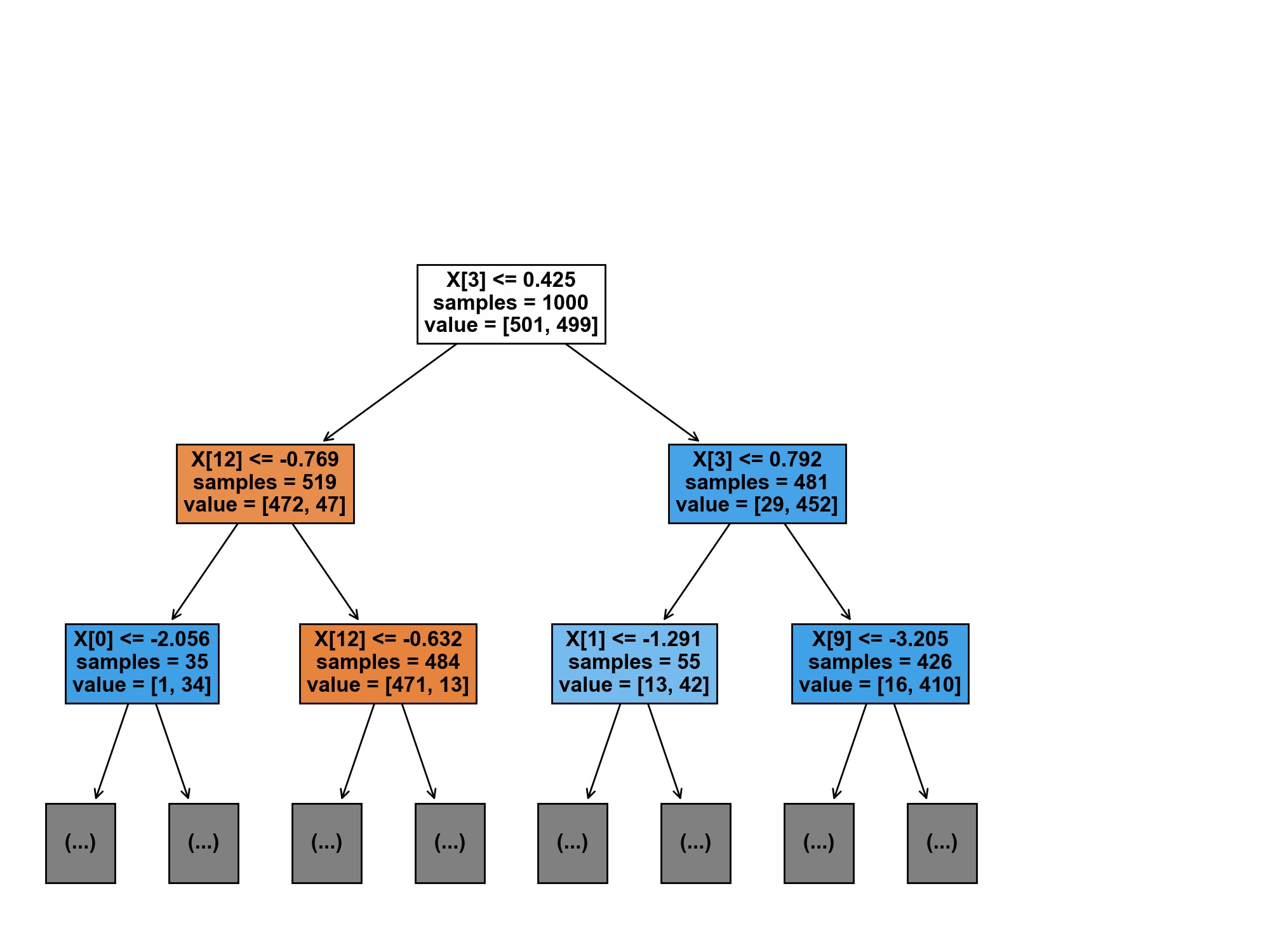
Great! In the output above, we get a glimpse into the tuning process: The random search draws 5 combinations (n_iter=5) of hyperparameters and evaluates each of these combinations in a 3 fold cross-validation (cv=3). The configuration with the best score is then selected for the model and used to fit it on the whole training set. Here, criterion=gini and max_depth=5 is the most potent configuration with an accuracy of $ 96% $.
This tuned decision-tree performsbetter than the one of the untuned logistic regression on the test set (see below).
1 | from sklearn.metrics import accuracy_score |
The models accuracy is: 0.944
Using the Optimal Hyperparameters in a different Model
We can also extract these optimal hyperparameters to specify them directly in our model. This extraction can be useful, if we want to use the model for adjacent purposes like for example visualizing a decision-tree in a graph.
See below for the implementations of the hyperparameters extraction and the final plot of the decision tree!
1 | best_params = rcv.best_params_ # get the best hyperparameters found by RS |
{'max_depth': 5, 'criterion': 'gini'}
Note how we need to unlist the dictioanry best_params by prefixing it with **best_params!
Finally, we make use of plot_tree to visualize our Decision-Tree below! Usually, we could try to interpret it and try to get a better intution for what our model is doing, however this does not make a lot of sense with simulated data.
1 | from sklearn.tree import plot_tree |
The most simple Machine Learning Pipeline